Bioinformatik
Forschungsschwerpunkt
Künstliche Intelligenz in der Proteindiagnostik
Die Künstliche Intelligenz (KI) ist ein essentiell wichtiger Ansatz, um das Potential der in PRODI etablierten molekularen und analytischen Methoden in der Protein-Diagnostik voll ausschöpfen zu können. Die Signaturen krankheitsspezifischer molekularer Veränderungen liegen in biomedizinischen Daten oft in verdeckter Form vor und sind nicht direkt für diagnostische Zwecke verwendbar. Hier kommt die künstliche Intelligenz ins Spiel: Wenn in klinischen Studien hinreichend große Datenbestände gesammelt werden, lassen sich die entscheidenden Muster mit Techniken wie zum Beispiel dem sogenannten Deep Learning aufdecken und etwa zur Unterscheidung von Subtypen von Krebserkrankungen verwenden. Der Forschungsschwerpunkt im Kompetenzbereich Bioinformatik liegt dementsprechend in der Etablierung von KI-Techniken, um Krankheitsmuster aufdecken und diagnostisch nutzen zu können.
Methodenentwicklung
Molekular Interpretierbare Künstliche Intelligenz
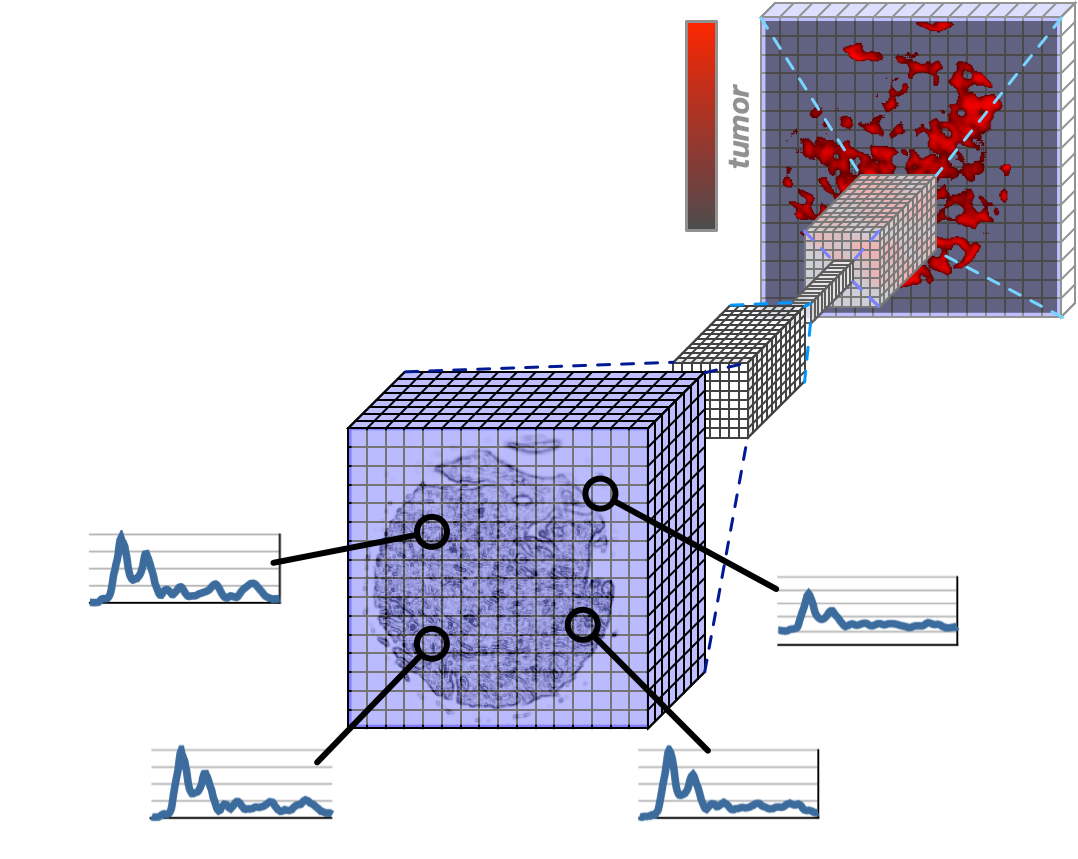
Im Mittelpunkt unserer Methodenentwicklung stehen Fragestellungen der interpretierbaren Künstlichen Intelligenz: Wenn ein KI-System eine diagnostische Einordnung einer Probe trifft, ist zunächst weder für Patienten noch für Mediziner nachvollziehbar, wie das KI-System zu dieser Entscheidung gelangt ist. Unser Forschungsansatz begegnet diesem Problem mit der Entwicklung von Algorithmen zur molekularen Interpretierbarkeit von KI-basierten Entscheidungen. Neben der eigentlichen Klassifikation des Krankheitsstatus besteht eine molekulare Interpretation aus einer zusätzlichen, erweiterten Vorhersage einer molekularen Eigenschaft der klassifizerten Probe. Der Vorteil von diesem Ansatz: Die vorhergesagte molekulare Eigenschaft kann an jeder einzelnen Probe von jedem einzelnen Patienten experimentell überprüft werden. Stimmt die erweiterte Vorhersage der molekularen Eigenschaft, so ist auch die Klassifikation des Krankheitsstatus vertrauenswürdig.
Derartige molekular interpretierbare KI-System erfordern die Entwicklung neuer Algorithmen und Herangehensweisen. Im Kompetenzbereich Bioinformatik in ProDi entwickeln wir solche Verfahren auf der Grundlage von tiefen neuronalen Netzen, also dem sogenannten Deep Learning.